





















广告位招租
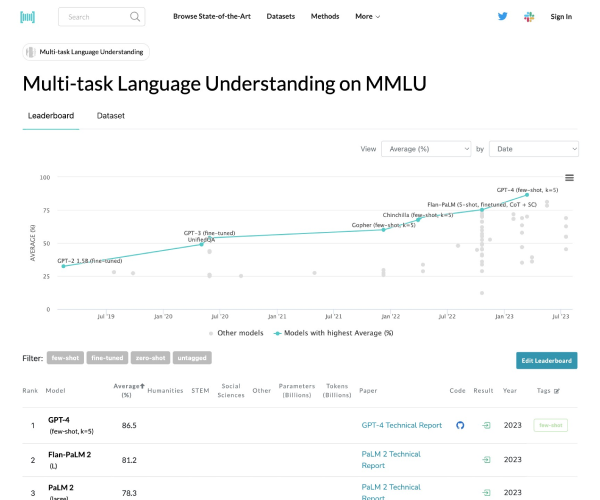
MMLU 全称 Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。
提示:若发现您的权益受到侵害,请立即联系客服,我们会尽快为您处理









