





















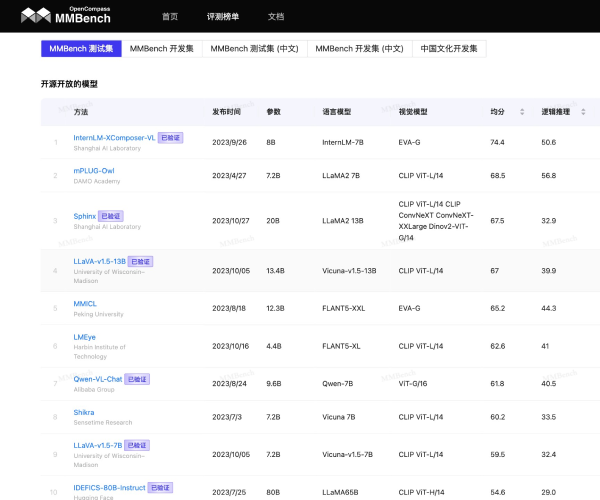
MMBench是一个多模态基准测试,由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学和浙江大学的研究人员推出。该体系开发了一个综合评估流程,从感知到认知能力逐级细分评估,覆盖20项细粒度能力,从互联网与权威基准数据集采集约3000道单项选择题。打破常规一问一答基于规则匹配提取选项进行评测,循环打乱选项验证输出结果的一致性,基于ChatGPT精准匹配模型回复至选项。
MMBench的特点和优势
- 基于感知与推理,将评估维度逐级细分。约 3000 道单项选择题,覆盖目标检测、文字识别、动作识别、图像
理解、关系推理等 20 个细粒度评估维度 - 更具鲁棒性的评估方式。相同单选问题循环选项提问,模型输出全部指向同一答案认定为通过,相比传统1次性通过评估 top-1 准确率平均下降 10% ~ 20%。最大程度减少各种噪声因素对评测结果的影响,保证了结果的可复现性。
- 更可靠的模型输出提取方法。基于 ChatGPT 匹配模型输出与选项,即使模型未按照指令输出也可准确匹配至最合理选项
提示:若发现您的权益受到侵害,请立即联系客服,我们会尽快为您处理










